Применение машинного обучения при формировании базы коммерческого назначения

В настоящее время становится популярным такой подход к извлечению информации, как машинное обучение. На базе его принципов и алгоритмов создается множество аналитических решений в бизнесе и процессы формирования коммерческих баз данных.
Методы получения знаний
Существует многообразие бизнес-задач и большинство из них решаются по одной методике. Методы, практически, не имеют зависимости от информационной модели; это есть набор дробных действий, сочетая их, можно построить аналитический механизм. В машинном обучении имеются шаги на которых выполняется подготовка данных, выбор информативных признаков, очистка, построение моделей, постобработка и интерпретация полученных результатов. Рассмотрим подробнее последовательность шагов, выполняемых на каждом шаге машинного обучения. Отбор признаков. Первым шагом в анализе является получение исходной выборки. И как показывает практика, это один из сложных этапов, и от которого больше всего зависит эффективность всего анализа. На базе отфильтрованных данных происходит построение модели, где необходимо участие экспертов для выдвижения гипотез и отбора факторов, влияющих на анализируемый процесс. Желательно, чтобы данные были уже собраны и преобразованы в единый формат. При отборе признаков часто используются удобные механизмы для подготовки выборки: запросы, фильтрация данных и сэмплинг.
Очистка данных.
Очистка и подготовка данных это очень важный шаг в любом проекте с машинным обучением. Почти всегда, полученные данные имеют плохое качество и содержат много «мусорной» информации. Вне зависимости от используемых технологий и алгоритмов, исходные данные перед использованием должны быть очищены. Более того, эта задача может представлять самостоятельную ценность в областях, не имеющих непосредственного отношения к анализу данных. Очистка данные включает в себя: подавление аномальных значений, заполнение пропусков, сглаживание, удаление дубликатов и противоречий и пр.
Трансформация данных.
Заключительным этапом преобразования данных является трансформация. Трансформация применяется для тех методов, при использовании которых исходные данные должны быть представлены в конкретном виде. Суть в том, что разным алгоритмам анализа необходимы подготовленные, различным способом, данные. Например, для прогнозирования необходимо преобразовать временной ряд при помощи скользящего окна или вычислить агрегированные показатели. К задачам трансформации данных относятся: скользящее окно, приведение типов, выделение временных интервалов, квантование, сортировка, группировка и пр.
Интерпретация.
В случае, когда извлеченные зависимости и шаблоны непрозрачны для пользователя, должны существовать методы постобработки, позволяющие привести их к интерпретируемому виду. Для оценки качества полученной модели нужно использовать как формальные методы, так и знания аналитика. Именно аналитик может сказать, насколько применима полученная модель к реальным данным. Построенные модели являются, по сути, формализованными знаниями эксперта, следовательно, их можно тиражировать. Найденные знания должны быть применимы и к новым данным с некоторой степенью достоверности.
Построение модели
Следующим шагом является построение модели. Зависимости и шаблоны должны быть нетривиальными и ранее неизвестными, например, сведения о средних продажах таковыми не являются. Знания должны описывать новые связи между свойствами, предсказывать значения одних признаков на основе других.
- Классификация – это зависимость входных данных от дискретных выходных.
- Регрессия – это зависимость между входными данными и непрерывными выходными.
- Кластеризация – это группировка данных руководствуясь свойствами этих данных. Данные внутри кластера должны иметь одинаковые свойства и отличаться от свойств данных других кластеров.
- Ассоциация – поиск закономерностей между связанными событиями. К примеру, можно привести следующее правило, что из события X следует событие Y. Такие правила называются ассоциативными.
Задача классификации отличается от задачи регрессии тем, что в классификации на выходе присутствует переменная дискретного вида, называемая меткой класса. Решение задачи классификации сводится к определению класса объекта по его признакам, при этом множество классов, к которым может быть отнесен объект, известно заранее. В задаче регрессии выходная переменная является непрерывной — множеством действительных чисел, например, сумма продаж задаче регрессии сводится, в частности, прогнозирование временного ряда на основе исторических данных.
Кластеризация отличается от классификации тем, что выходная переменная не требуется, а число кластеров, в которые необходимо сгруппировать все множество данных, может быть неизвестным. Выходом кластеризации является не готовый ответ (например, плохо/удовлетворительно/хорошо), а группы похожих объектов – кластеры. Кластеризация указывает только на схожесть объектов, и не более того. Для объяснения образовавшихся кластеров необходима их дополнительная интерпретация. Перечислим наиболее известные применения этих задач в экономике.
Классификация используется, если заранее известный класс, например, при отнесении нового товара к той или иной товарной группе, клиента к какой-либо категории (при кредитовании – по каким-то признакам к одной из групп риска). Регрессия используется для установления зависимостей между факторами. Например, в задаче прогнозирования зависимая величина – прибыль компании, а факторы, которые влияют на нее, может быть количество проданного товара, продуктивность работников, экономическая обстановка страны и т. д. Или, например, скоринг при оценке кредитоспособности частных лиц, которая имеет зависимость от возраста, профессии, занятости, наличия имущества и т.д.
Кластеризация может использоваться для сегментации и построения профилей клиентов. При достаточно большом количестве клиентов становится трудно подходить к каждому индивидуально, поэтому их удобно объединять в группы — сегменты с однородными признаками. Выделять сегменты можно по нескольким группам признаков, например, по сфере деятельности, по географическому расположению. После кластеризации можно узнать, какие сегменты наиболее активны, какие приносят наибольшую прибыль, выделить характерные для них признаки. Эффективность работы с клиентами повышается благодаря учету их персональных предпочтений.
Ассоциативные правила позволяют выявить одновременно приобретаемые товары или услуги. К примеру, это можно использовать в рекомендательной системе интернет магазина, для более эффективных продаж. Когда пользователь покупает, например, радиоуправляемую машину, то нужно предложить ему также купить и набор батареек к ней. Последовательные шаблоны также используется при эффективном планировании продаж и предоставлении услуг. У них велико сходство с ассоциативными правилами, но при анализе важен порядок совершения событий. К примеру, если клиент, в банке, открыл счет до востребования и приобрел ценные бумаги, то с вероятностью 70% при следующем обращении он возьмет депозитный сертификат.
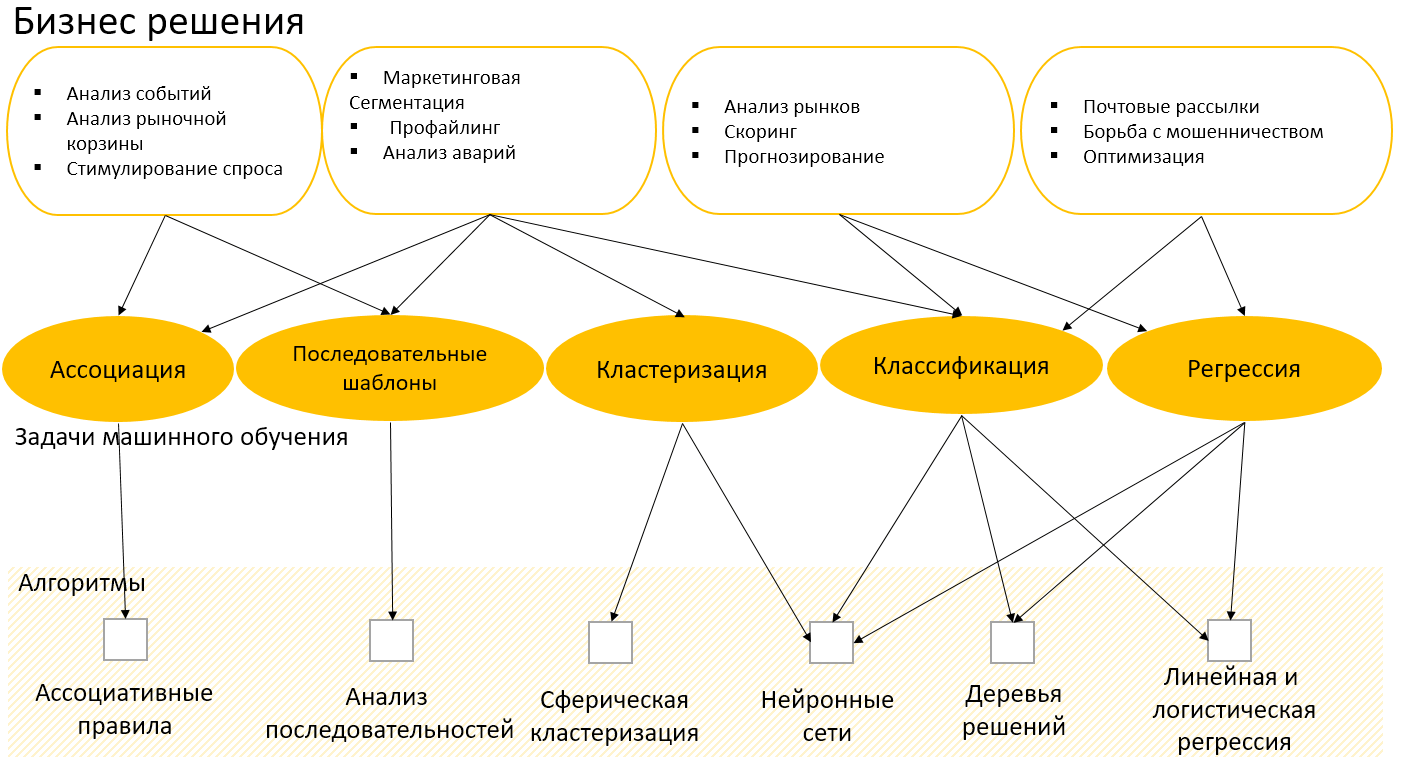
Выше упомянуты основные классы задач, которые возможно решить посредством алгоритмов машинного обучения. Также существует несколько современных подходов, которые используются вместе с алгоритмами машинного обучения, делая анализ более точным. К примеру, генетические алгоритмы способны эффективно решать задачи оптимизации, которые используются для обучения нейронных сетей, карт Кохонена, логистической регрессии, при отборе значимых признаков. Математический аппарат нечеткой логики также успешно включается в состав практически всех алгоритмов машинного обучения; так появились нечеткие нейронные сети, нечеткие деревья решений. При помощи нечеткого поиска в базах данных, оперируя нечеткими понятиями, позволяет сделать нечеткие срезы, благодаря которым возможно, к примеру, отбирать релевантные объекты. И подобных примеров множество. В наше время компании собирают огромный объем данных, на их основе можно принимать различные бизнес-решения. Дальнейшим шагом развития систем, которые принимают решения руководствуясь существующими данными, являются системы автоматизированного принятия решения. Точнее, виртуальные помощники, дающие советы по поддержке и развитию бизнеса.
Опубликовано в сборнике “Огаревские чтения 16”