Отбор признаков пользователя социальной сети для построения модели машинного обучения

В статье рассматривается задача и проблема отбора признаков для обучения модели машинного обучения для классификации пользователей в социальных сетях. Автоматическое определение характеристик пользователей, такие как интересы или отношение к конкретному слою населения по собранной информации с профиля пользователя, такой как поведение, структура социальных связей и данных естественного языка.
Несомненно, социальные сети стали частью жизни миллиардов людей и трудно представить жизнь без них. В дополнение к общению с друзьями, семьей, знакомыми, социальные сети используются для чтения актуальных новостей и являются огромной площадкой для обмена информацией. И уже давно не секрет, что здесь ведут свою деятельность как малые предприниматели, так и крупные корпорации. С активным развитием интернета социальные сети стали одним из ключевых маркетинговых инструментов. Ведь среди пользователей социальных сетей есть аудитория всех возрастов и разных слоев населения.
На площадках социальных сетей можно успешно продвигать свой продукт без глубокого анализа аудитории, но можно получить значительно больше пользы если у целевого пользователя имеются демографические атрибуты, интересы, хобби, либо определенное поведение, на основе данных социальной сети. Такая информация позволяет, к примеру, предлагать персонализированные предложения продуктов, более подходящие для этого пользователя, или определять потенциальных покупателей и переходить к более активным методам продаж.
Как правило, во многих сервисах каждый пользователь имеет имя, возраст, местоположение и короткое описание интересов, или ссылки на другие социальные сети. Но этого иногда недостаточно или информация может быть не корректной. Все это требует усовершенствования систем сбора и обработки данных.
Основная модель классификации пользователя
Данные, которые представляют информацию о пользователе в соц. сетях, можно разделить на 4 основных типа: профиль, поведение, текстовый контент (сообщения, публикации, комментарии) и данные от самих социальных сетей (например, время посещений, количество подписчиков\подписок). Четырех типов вполне достаточно для извлечения признаков модели классификации общего назначения. Перед нами встают задачи:
-
Общая оценка относительного влияния признака, надежности и обобщения потенциальных возможностей для классификации пользователей.
-
Исследование значения лингвистической информации для классификации пользователей.
Признаки из профиля пользователя
Многие сервисы, по умолчанию, отображают информацию профиля, такие как имя пользователя, местоположение и короткое резюме о пользователе.
Помимо этого, все популярные API социальных сетей предоставляют доступ к другой информации, такие как число подписчиков, друзей, публикаций и т.д.
Но при сборе данных с социальных сетей можно столкнуться с рядом проблем:
-
Ограниченный доступ или блокировка для автоматического сбора информации.
-
Приватность данных – часто пользователи устанавливают настройки приватности, что делает недоступными извне многие атрибуты профиля.
-
Слабая структурированность данных – некоторые социальные сети либо не имеют API, либо с большими ограничениями, что делает сбор данных весьма проблематичным. Для этого необходимо «вручную» получать HTML и разбирать структуру страницы
Поведение
Характеристика поведения пользователя охватывает ряд статистики взаимодействия с сервисом: среднее число сообщений в день, число ответов, число повторных публикаций (репостов) и т.п. Подобные данные могут быть вполне пригодны для обучения модели. К примеру, статистика показывает, что люди, которые реже делают публикации имеет более уникальный контент сравнимо с теми, кто делает это чаще и в публикациях содержится URL на сторонние сайты.
Текстовый контент
Текстовый контент имеет информацию об основных темах, представляющих интерес для пользователей. Простая текстовая информация помогает классифицировать пользователей по комментариям, блогам, по разговорам и сессиям поиска.
Далее разберем основные свойства текстового контента.
Моделирование по тематике
Взяв во внимание n классов, где каждый класс \(c_i\) представляет набор пользователей \(S_i\). Каждому слову \(w\), присвоенному, по крайней мере, одному пользователю, присваивается балл каждому из классов. Значение балла высчитывается условной вероятностью класса по формуле: \begin{equation} proto\left(w,c_i\right)=\ \frac{|w,\ S_i|}{\sum_{j=1}{|w,\ S_j|}} \end{equation}
где \(|w,\ S_i|\) это количество выдач слова \(w\) для всех пользователей класса \(c_i\). Для каждого класса пользователей сохраняется \(k\) тематических слов с высокой оценкой. \(n*k\) тематических слов собирается со всех классов и служат в качестве признаков представляющих конкретного пользователя: для каждого тематического слова \(wp\), пользователю \(u\) присваивается оценка.
\begin{equation}
f_proto_wp\left(u\right)\ \ =\ \frac{|u,\ wp|}{\sum_{w\ \epsilon \ W_u}{|u,\ w|}}\
\end{equation}
где \(|u,\ wp|\) количество выдач слова \(w\) пользователю \(u\), и \(W_u\) это набор всех слов выданных пользователю \(u\). Для каждого класса, пользователю назначается обобщенный признак:
\begin{equation}
f_{proto_{c\left(u\right)}}=\ \frac{\sum_{wp\ \epsilon \ WP}{\left|u,\ wp\right|}}{\sum_{w\ \epsilon \ W_u}{\left|u,\ w\right|}}
\end{equation}
где \(wp\) это набор тематических слов для класса \(с\).
Классификация по хештегам
Во многих социальных сетях можно использовать хештеги для обозначения основной темы публикации. Чаще всего те же самые или похожие хештеги используются для упрощенного поиска информации среди похожих публикаций. Классификация по хештегам происходит тем же путем, что и по тематическим фразам. Учитывая, что набор \(S_i\) для класса \(c_i\), где \(w\) будет содержать все хештеги из публикации. Тогда можно получить набор тем хештегов применяя формулу 1. В конечном счете нужно сохранить хештеги с высокой оценкой для каждого класса, и вычислить признаки формулами 2 и 3.
Общий LDA
Используем адаптированную LDA модель – латентное размещение Дирихле. На практике LDA модель дает хорошие результаты для различных наборов данных. В LDA предполагается, что каждое слово в документе порождено некоторой латентной темой, при этом в явном виде модулируется распределение слов в каждой теме, а также априорное распределение тем в документе. Темы всех слов в документе предполагаются независимыми. Документ может соответствовать не одной теме.
Наша гипотеза заключается в том, что пользователь может быть представлен как мультиномиальное распределение по темам. Это распределение может помочь с классификацией.
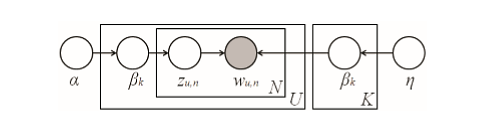
Модель описана на рисунке 1. Фактически LDA модель является трехуровневой байесовской сетью, которая порождает документ из набора тем. Получаем число \(U\) пользователей и число \(K\) тем, каждый пользователь u представляет мультиномиальное распределение \(\theta_u\) над темами, которое представляется распределением Дирихле с параметром \(a\) (обычно \(a\) принимается равным 50/K). Также тема — это представление по мультиномиальному распределению \(\beta_k\), представленное из другого распределения Дирихле с параметром \(\eta\) (обычно параметр \(\eta \) = 0.1, увеличение \(\eta\) ведет к более разреженным тематикам). На каждую позицию слова \(n\) пользовательского словаря выделена тема \(z_{u,\ n}\) из \(\theta_u\), и слово в позиции \(w_{u,\ n}\) из представления \({\beta }_{z_{u,\ \ n}}\).
Настроение
В некоторых случаях необходимо определить эмоциональное направление публикаций по отношению к определенному бренду или продукции.
Набор публикаций заданного пользователя \(u\) и каждый из терм \(t\), сначала анализируется на число положительных, отрицательных и нейтральных настроений выраженных относительно \(t\). Для каждой публикации и термы \(t\) вычисляется доминирующее настроение по фразам, с окном \(k=4\) слов слева и справа от \(t\).
Итогом является агрегация признаков, указывающих на общее настроение пользователя относительно целевого класса, к примеру: среднее и стандартное отклонение вышеуказанных признаков во всем наборе терминов; количество терминов \(t\), о которых пользователь имеет в основном положительное, отрицательное или нейтральное мнение.
Взаимодействия
Большую роль в классификации имеют связи, установленные пользователем с другими пользователями социальной сети, также его ответы, репосты, понравившиеся публикации.
Друзья
Несложно заметить, что люди, увлекающиеся автомобилями, с большей вероятностью добавляют в друзья своих единомышленников и вступают в группы с автомобильной тематикой. Можно предположить, что пользователи других классов также могут поделиться конкретными аккаунтами друзей.
Для того чтобы загрузить набор классов профилей друзей \(F\) можно использовать тот же механизм классификации тематических фраз, а именно формулу 1. Затем необходимо получить следующие признаки для данного пользователя \(u\): количество профилей в \(F\), на которые пользователь подписан; процент \(F\) профилей которые подписаны на \(u\); процент аккаунтов подписанных на \(u\).
Ответы, комментарии и репосты
Здесь тот же принцип, что и с друзьями, признак показывает, что пользователь имеет тенденцию комментировать, делать репосты, добавлять в избранное контент интересующих его людей или групп. Классифицировать по этому признаку можно по тому же принципу как, по тематическим словам, и хештегам.
Сообщества
В реальном мире для человечества вполне характерно объединяться во всевозможные сообщества по интересам, роду деятельности, социального круга. Та же самая картина наблюдается и в социальных сетях.
Анализ сообществ пользователя социальной сети также является важным критерием при классификации. Информация о сообществах, социальной сети на глобальном уровне находит применение в системах рекомендаций, фильтрации и спама и многих других приложениях. Как правило, сообщества в социальных сетях имеют внутреннюю категоризацию, что очень упрощает задачу при классификации пользователей, вступивших в них.
Практическое применение
Эта задача особенно привлекательна бизнесу, так как она позволяет идентифицировать своих потенциальных клиентов. Задача предварительной оценки того, насколько интересует конкретный товар или услуга, определенного пользователя.
Для примера, выберем потенциальных клиентов определенного автопроизводителя Audi. Выборка будет состоять из равного количества пользователей, которые уже подписаны на официальные страницы Audi, и которые не следят за новостями этого бренда. Также проведем классификацию пользователей по другим критериям и оценим точность классификации.
На эксперименте было выявлено, что можно определить потенциального подписчика Audi можно определить с весьма разумной точностью 0.85 и полнотой 0.84.
По результатам был сделан вывод, что лингвистическая информация и описание профиля играют большую роль. Признак соотношения между подписчиками и друзьями может стать полезным, предполагая, что подписчики бренда - это пользователи, которые следуют за другими, больше, чем за ними. В рамках набора лингвистических признаков, признак основанный на хештегах работает лучше всего, когда признаки настроения имеют наивысшую точность, но низкий уровень полноты. Последний результат обусловлен двумя причинами: рассматривает настроение публикаций со словом «Audi»; люди очень редко употребляют название бренда в своих публикациях.
В статье была представлена общая модель классификации пользователей в социальных сетях, которая показывает, что классификация пользователей является вполне выполнимой задачей. Лингвистические особенности, особенно на основе темы, оказываются вполне надежными признаками для построения модели. Явные признаки, представляемые социальной сетью, могут неплохо помочь в случае, если целевой класс богат знаменитостями с активным присутствием их в этой сети (это довольно полезно и важно для крупного бизнеса).
Одной из доминирующих тенденций развития социальных сетей как социокультурного феномена является более глубокое понимание особенностей социального поведения человека и, как следствие, создание новых средств для самовыражения, а также обмена информацией и опытом. Разумно ожидать дальнейшего расширения пользовательской модели и функционала социальных сетей, что приведет к появлению новых типов данных, что приведет к упрощению задачи классификации.
Опубликовано в “Информационные технологии моделирования и управления, 2017, №6(108)”